AxyTrek (Technosmart) やNinjaScan (Little Leonardo) などのロガーには、GPSによる緯度経度情報と加速度などを含むさまざまなセンサーデータが含まれます。それぞれのセンサーでサンプリング間隔が異なり、加速度データが不要だという場合には、元のデータ(data.csv)*からGPSに関係する項目のみを抽出してdata_gps.csvとして保存するこのプログラムを利用してみてください。
*BiPでOpenデータとなっているKatsufumi Sato (Atmosphere and Ocean Research Institute, University of Tokyo) 提供のオオミズナギドリのデータ (title: 9B41870_TS-AxyTrek_Movebank_YNo.6_release20210824) の一部を使用しています。
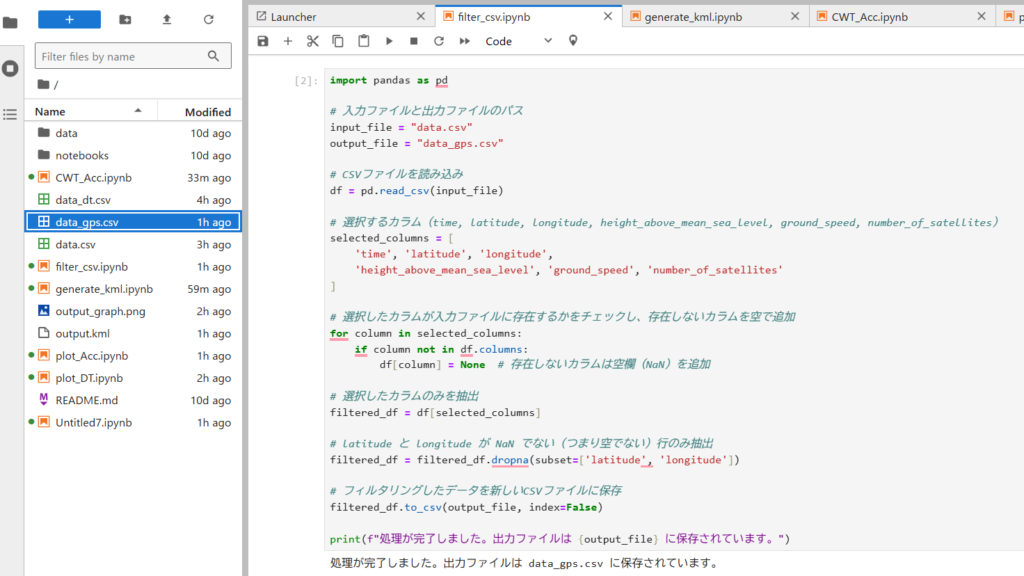
以下のPythonコード(filter_csv.py)をテキストエディタで開き、JupyterLiteのノートブックにコピーして実行(右▼をクリック)します。
import pandas as pd
# 入力ファイルと出力ファイルのパス
input_file = "data.csv"
output_file = "data_gps.csv"
# CSVファイルを読み込み
df = pd.read_csv(input_file)
# 選択するカラム(time, latitude, longitude, height_above_mean_sea_level, ground_speed, number_of_satellites)
selected_columns = [
'time', 'latitude', 'longitude',
'height_above_mean_sea_level', 'ground_speed', 'number_of_satellites'
]
# 選択したカラムが入力ファイルに存在するかをチェックし、存在しないカラムを空で追加
for column in selected_columns:
if column not in df.columns:
df[column] = None # 存在しないカラムは空欄(NaN)を追加
# 選択したカラムのみを抽出
filtered_df = df[selected_columns]
# latitude と longitude が NaN でない(つまり空でない)行のみ抽出
filtered_df = filtered_df.dropna(subset=['latitude', 'longitude'])
# フィルタリングしたデータを新しいCSVファイルに保存
filtered_df.to_csv(output_file, index=False)
print(f"処理が完了しました。出力ファイルは {output_file} に保存されています。")
JupyterLiteの左のメニューバーに出力ファイル(data_gps.csv)が保存されていることを確認し、ダウンロードして使用してください。
コードの以下の部分を変更することで、出力ファイルに含まれる項目が変わります。適宜変更してご利用ください。
selected_columns = [
'time', 'latitude', 'longitude',
'height_above_mean_sea_level', 'ground_speed', 'number_of_satellites'
]
以下のように変更することで、三軸加速度データのみを抽出することもできます。その場合には出力ファイル名も”data_acc.csv”などと変更してください。
selected_columns = [ 'time', 'acceleration_longitudinal', 'acceleration_lateral', 'acceleration_dorso_ventral' ]